Xscaping Limits Blog Series #3: Xscape the Copper Wall

In our last blog, we established that the bandwidth and power of interconnect fabric is directly correlated to the Tokens/S/MW metric of the inference cluster. High-bandwidth and low-power interconnect fabric is critical for scaling inference. In other words, Tokens/S/MW for Inference Hardware is correlated to BW Perf/W of Interconnect Fabric. In this blog, let's try to dive deeper to understand the limitations of the incumbent interconnect fabric implementations.
For decades, copper interconnects have been the backbone of computing infrastructure and interconnect fabrics. They are highly effective for short-range communication, particularly within semiconductor packages or a single data center rack. Copper is a mature, well-tested, relatively cheap solution, and is already deeply embedded in how modern computing systems are built. On the surface, it seems like a perfect solution. But as AI systems scale, copper is reaching a point where its side effects – like signal loss and excessive power consumption – are no longer edge cases that can be engineered away. Now, copper comprises the primary constraints on the system as a whole.
When electrical signals travel through copper, they degrade due to a range of factors, from physical resistance to electromagnetic interference. This is manageable and poses little issue at low data rates and over short distances. However, modern AI systems operate at extreme bandwidths. They require immense amounts of data to be moved between accelerators, memory, and networking hardware in real time, at scales far surpassing what copper interconnects are built to handle without significant signal degradation.
To maintain performance, systems rely on increasingly complex compensation techniques, like equalization and signal conditioning. Each additional layer yields the dual effects of helping to preserve signal integrity but also adding power consumption and latency, plus further complicating architectures. These challenges only become more severe as the distance between components increases. Copper can still be engineered effectively across a board or within a rack, but beyond rack scale, physical limits creep in quickly as distributed electron transport becomes increasingly lossy over distance. Maintaining high-bandwidth electrical communication over longer ranges requires huge amounts of energy (and subsequently, money).
These limitations are currently colliding with the structure of today’s AI workloads. Training and inference rely on enormous parallel systems involving thousands of accelerators, constantly exchanging data at speed. Inference systems, especially those behind agentic AI workloads/long-context reasoning, amplify this demand significantly by requiring data to be moved across the broader data center fabric. It is at this “escape” layer, where data leaves the package and enters the fabric, that copper interconnects show their most critical constraints.
Inside chips and packages, copper can move data with extremely high bandwidth extremely efficiently. But as soon as those signals exit the rack, “escape” bandwidth can drop by more than 100x (Figure 1) due to heightened resistance and low signal integrity, especially without costly compensation circuitry mitigating the effects. This sharp tapering of “escape” bandwidth is what directly throttles throughput at the system level: even the world’s fastest compute units will still stall if data cannot arrive when it’s needed. As AI workloads require vast quantities of data to flow continuously, they are particularly susceptible to this bottleneck, and its effects on end users are tangible.
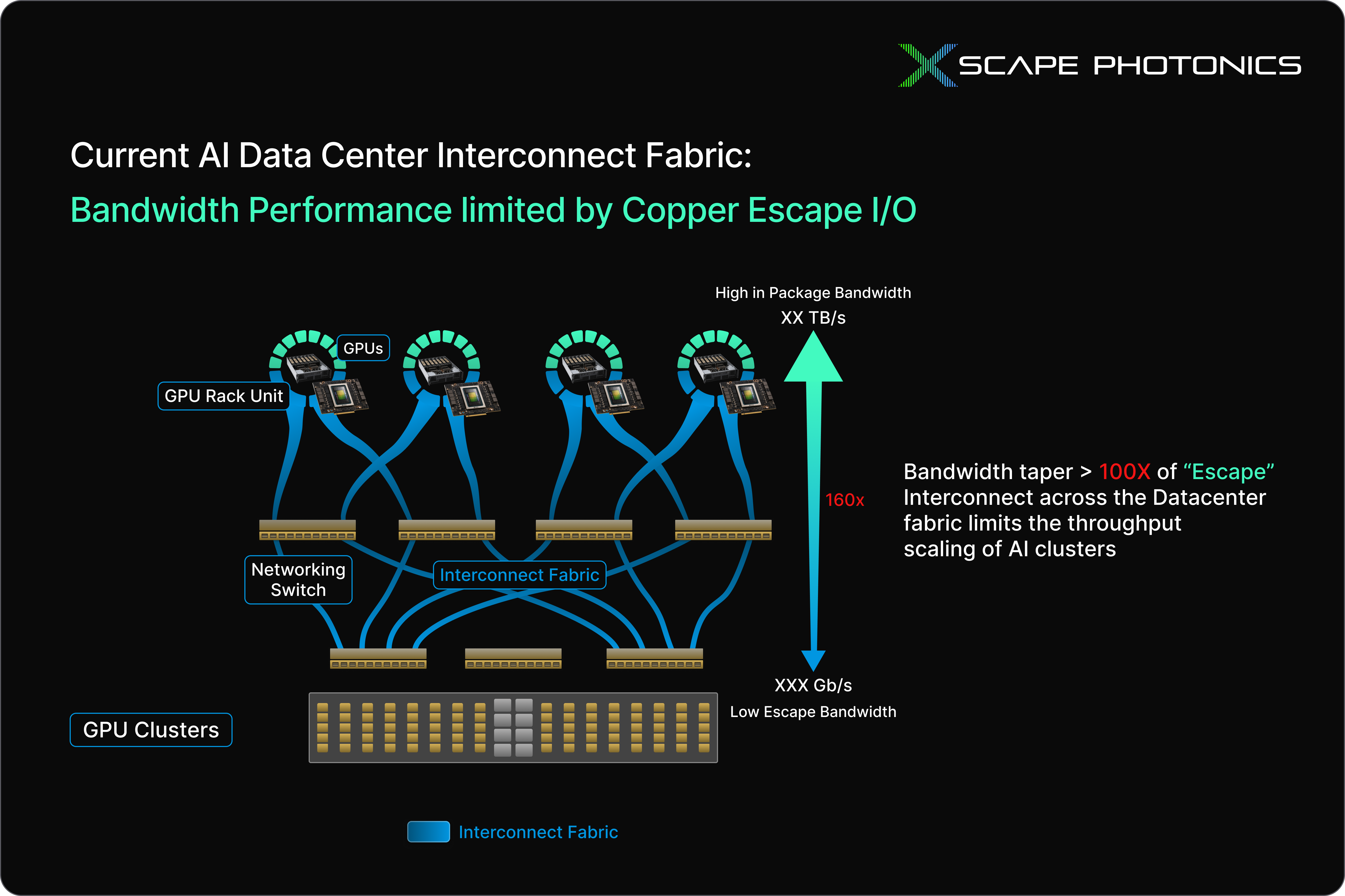
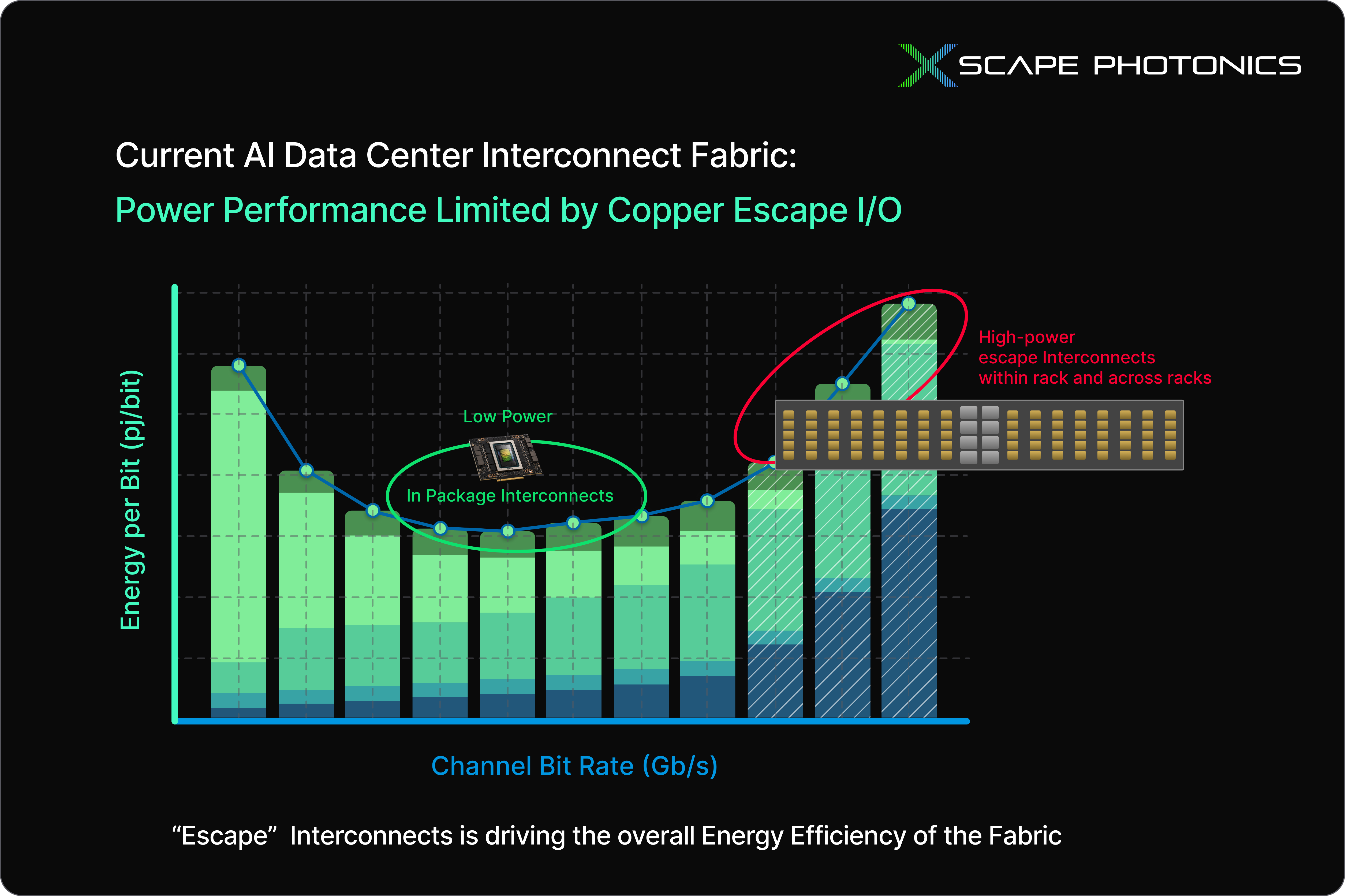
The problem also extends to energy efficiency. In power terms, on-chip and in-package communication via copper traces is not expensive, but escape input/output (I/O) across copper links consumes dramatically more energy per bit than alternatives. Going back to the BW Perf/Power metric, the numerator (performance) and denominator (power) of system efficiency (Figure 2) are dictated by the limitations of these “escape” interconnects. Practically, cracking the code of escape bandwidth and the associated power drain would unlock a new class of reasoning hardware. Until then, AI clusters face a hard limit on performance. There is a need to escape the copper-driven escape interconnect wall.
Acknowledgements: Sander Arts, Wireside Communications, Prof. Keren Bergmen and Hessam Mohajeri


