Xscaping Limits Blog Series #2: Xscape Al Infrastructure Limits- Scaling Al Beyond Compute

The AI revolution promises to transform everything, but it won’t. At least, not unless data center fabric networks transform first.
As the capability of agentic AI continues to evolve at an unprecedented pace, a new challenge is emerging at the heart of modern data centers. Attention has mostly focused on the rapid advancement of GPUs and specialized AI accelerators, but another critical component is quietly becoming the limiting factor: the fabric that connects them.
While the capabilities of AI agents depend on training, the functional deployment of those models in our everyday personal and professional lives depends on inferencing, or the ability of an agent to respond to new data and operate in real time. But it’s facing a significant problem: as agents start to reason, throughput begins to degrade.
The new performance metric of inferencing for an AI agent is tokens-per-second-per-megawatt (TPS/MW); simplified, that is performance per watt for an AI Inference Cluster (Figure 1).
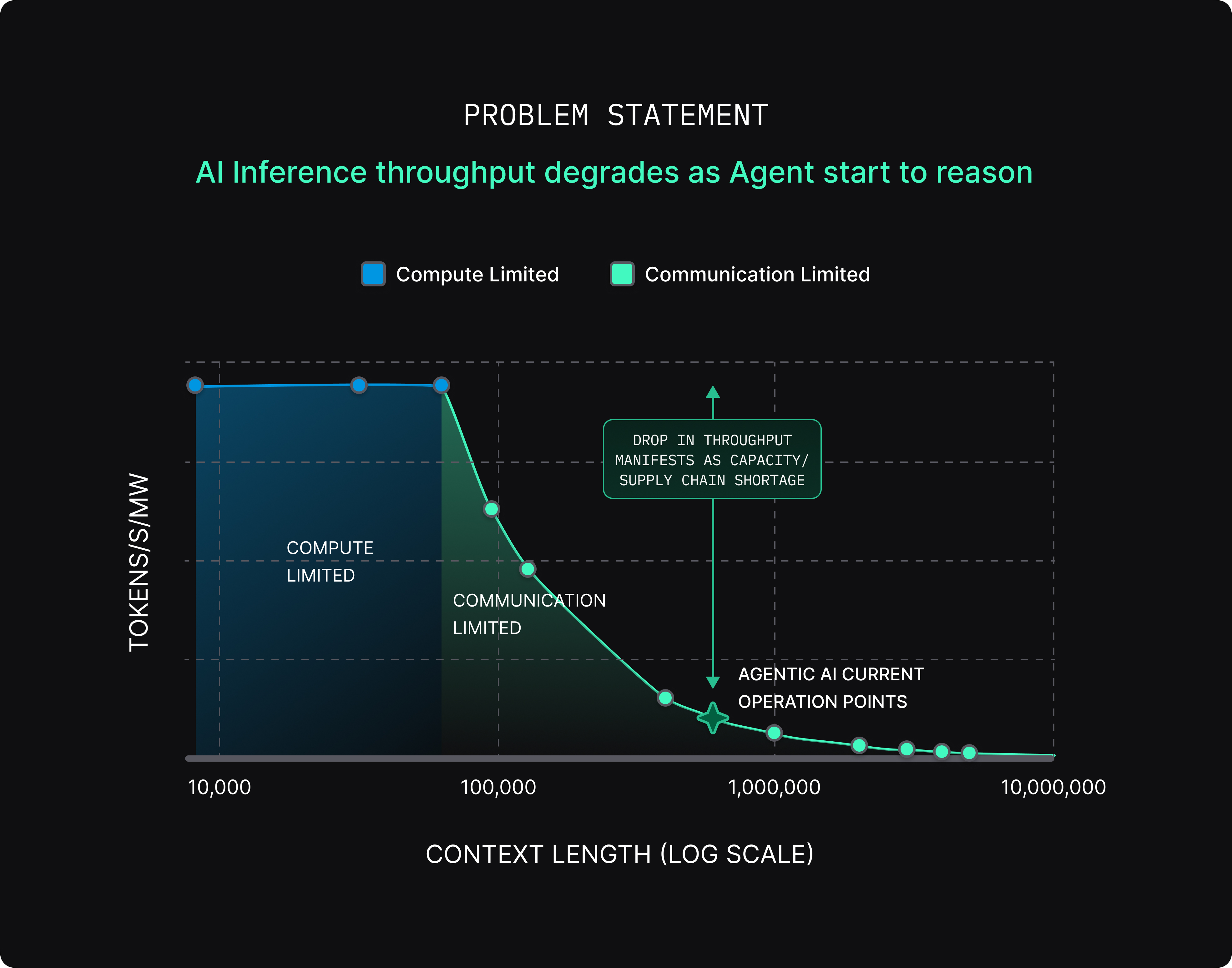
As an agent starts to think and reason, it processes more data at longer context lengths, causing the underlying inference hardware to enter a domain where performance becomes communication-limited. The performance-per-watt ratio degrades drastically with increasing context length due to exponential increase in data traffic; so, the industry ends up deploying significantly more compute than needed to meet the total token demand. In other words, hardware inefficiency in inference hardware translates to industry-wide compute and supply chain shortage.
So, what does it take to meet the desired token demand efficiently? Keep the Inference System Compute bound even at large context length.
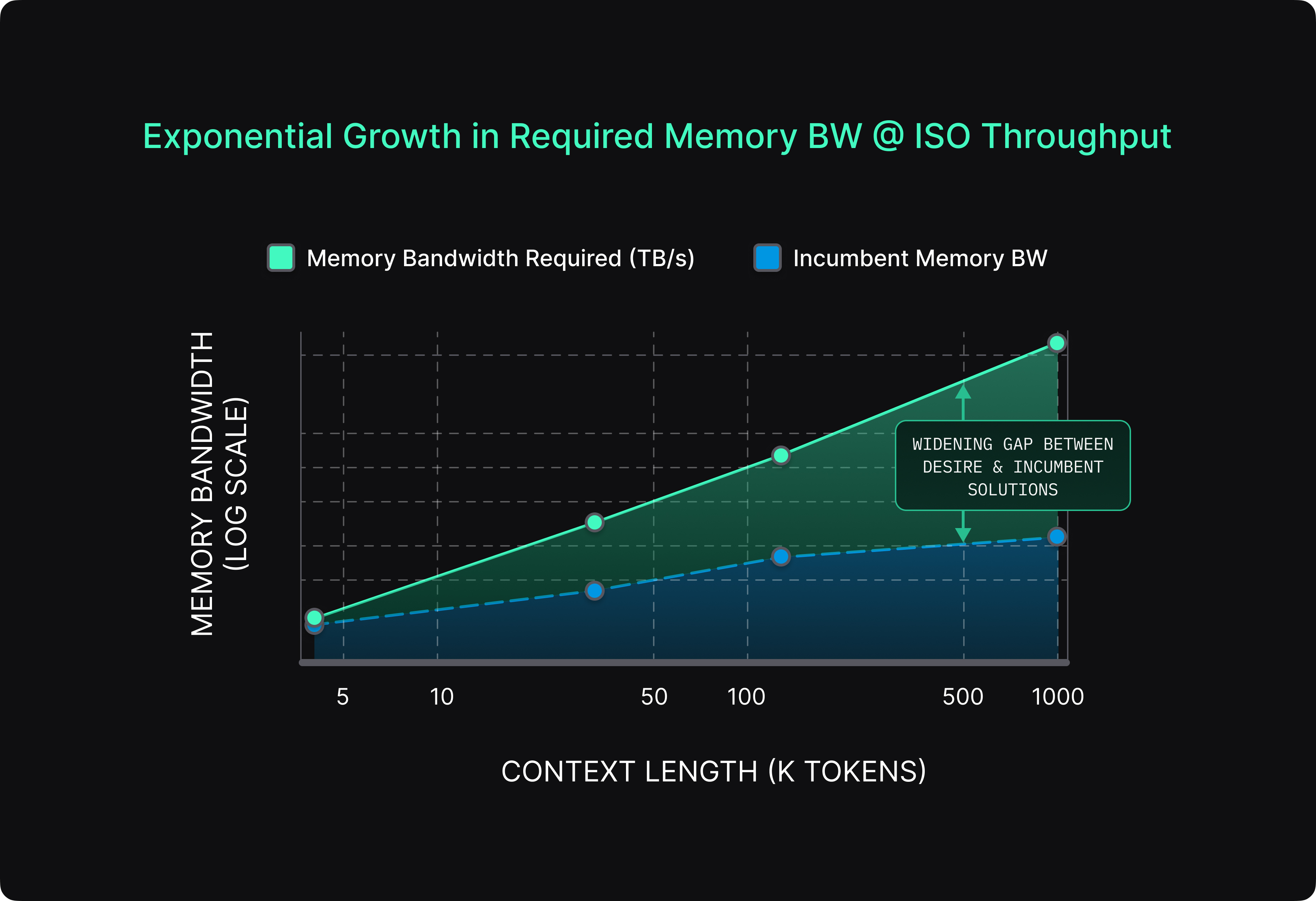
This requires an exponential growth in interconnect bandwidth to the memory with context lengths. This is where the bottleneck forms. Interconnect bandwidth (the speed at which data can travel between GPUs and memory) is struggling to keep up with the demand for Agentic AI applications. As noted in my recent blog post, there is a massive gap between the human brain—which performs complex reasoning tasks using roughly 20 watts—and modern AI inference systems that can consume close to 1 megawatt for similar workloads, exposing a roughly 50,000x efficiency gap.
Even when individual processors become faster, the overall system can slow down if the network cannot meet the exponential growth in required memory bandwidth (Figure 2) and this gap is widening with more sophisticated tasks. In many modern AI clusters, processors spend valuable time waiting for data from memory rather than performing computation.
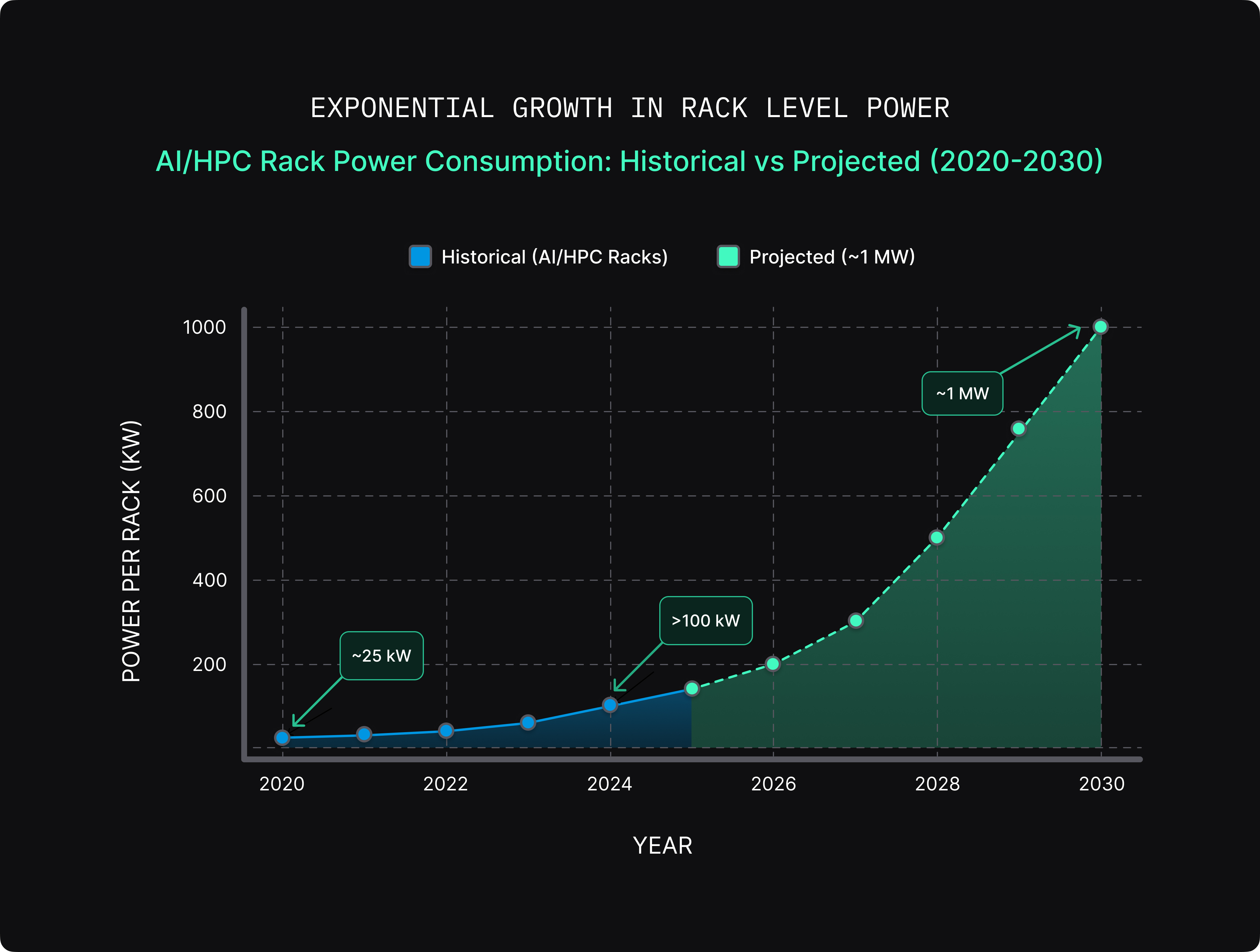
Even the current growth in bandwidth is coming at a high cost of power consumption that further limits the Perf/W metric. As clusters grow larger, the networking infrastructure required to support them becomes increasingly energy intensive. High-speed optical links, switching fabrics, and networking hardware add significant power demands to already massive data centers. The scale of these facilities has grown so large that they are now measured in megawatts of power consumption, rather than simply by the number of servers they contain (Figure 3).
In other words, the challenge facing AI infrastructure is shifting. The question is no longer just how to build faster chips, but how to connect vast numbers of them efficiently, reliably, and sustainably. Essentially, there is a massive need to build a new foundation for how AI systems communicate at scale.
The future of AI may depend just as much on advances in networking technology as it does on improvements in processors themselves. Because in the race to scale artificial intelligence, the next breakthrough may not come from better GPUs; it may come from better networks.
Acknowledgements: Sander Arts, Wireside Communications, Karthik Vaithianathan


